LangGraph a agent orchestrace: nový standard pro AI agenty
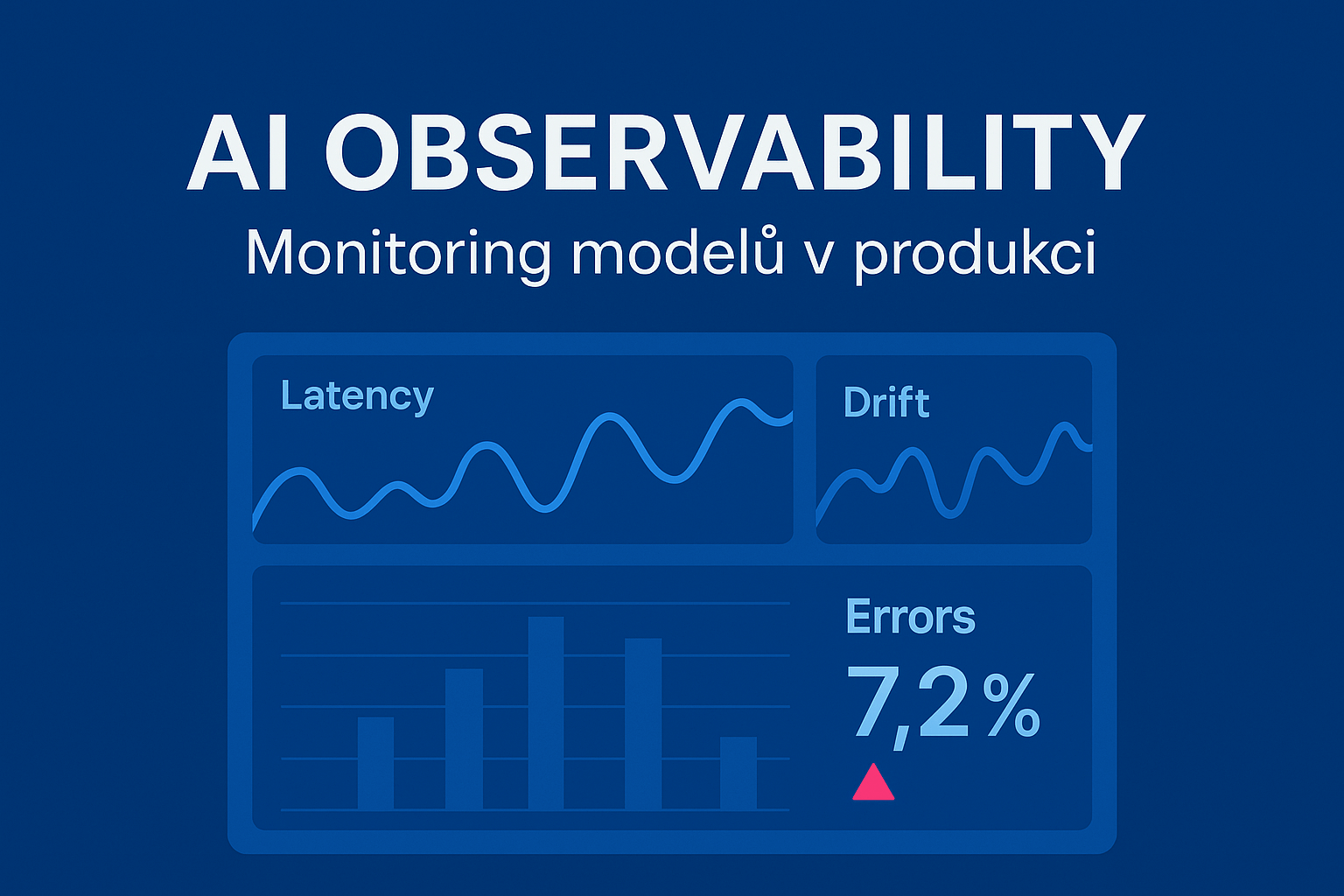
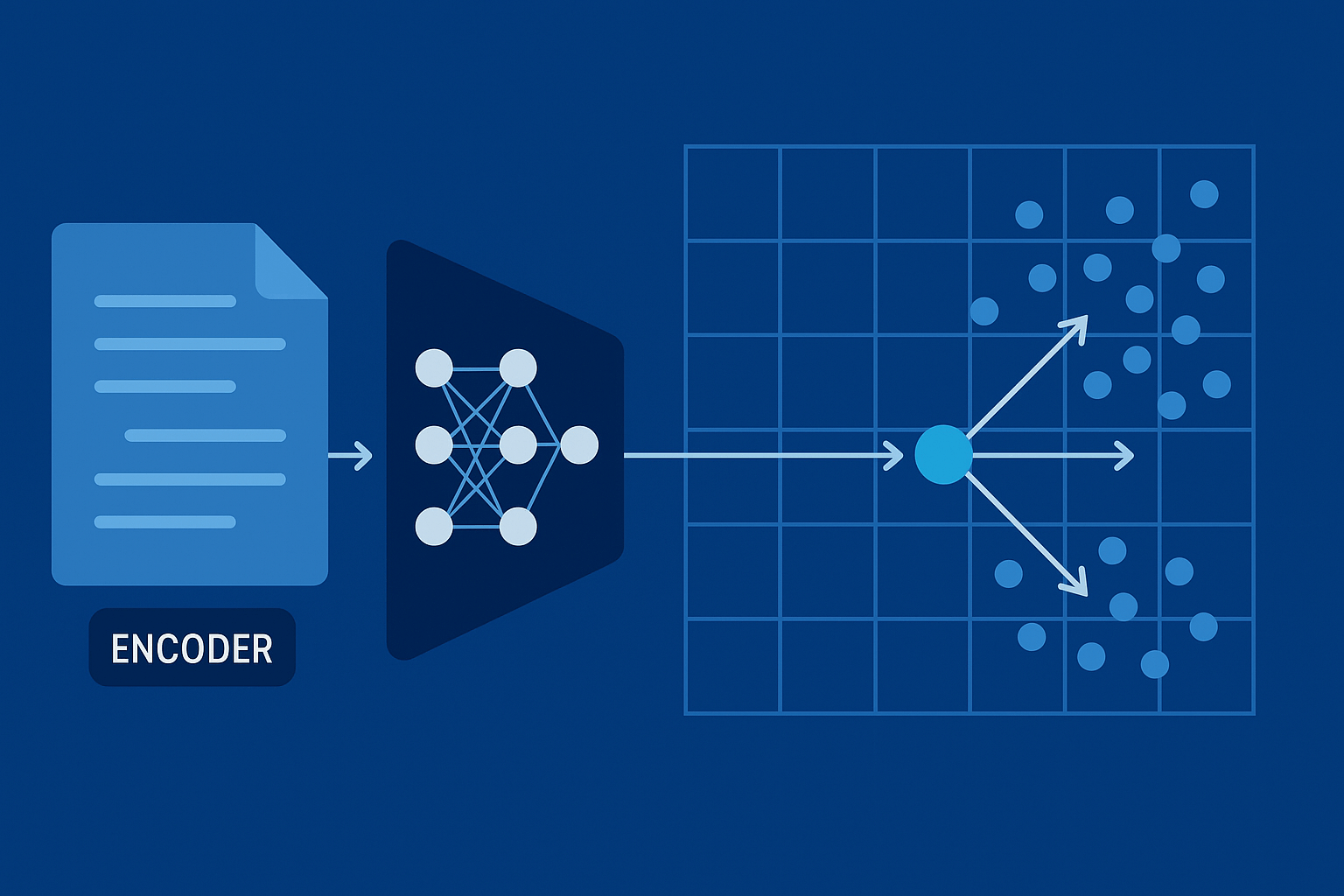
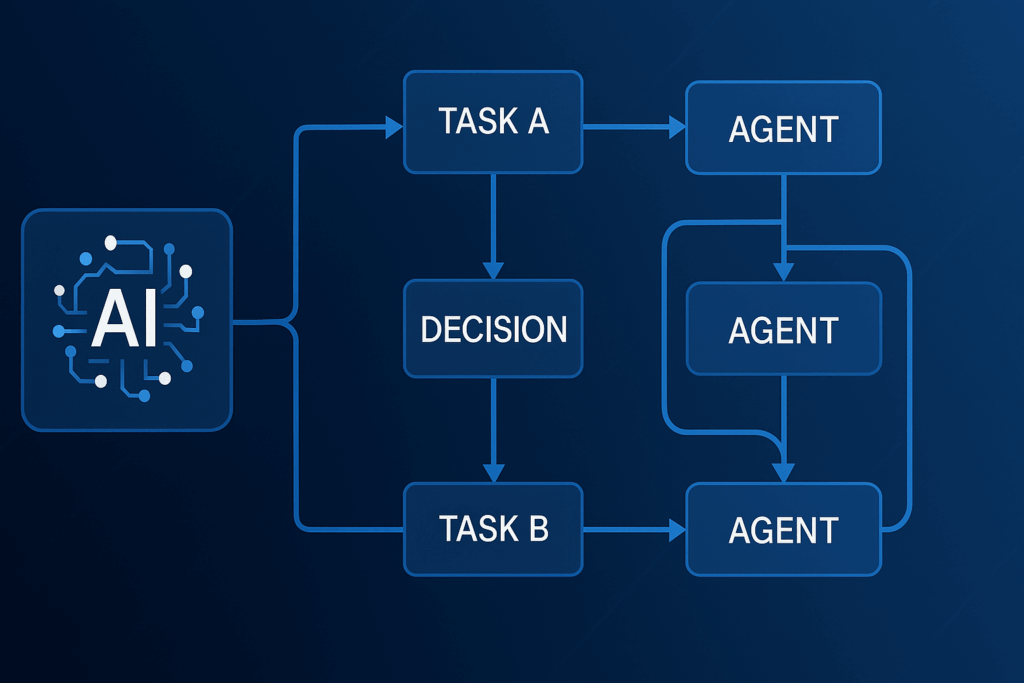
Jak funguje LangGraph, jak stavět multi-agentní systémy a kdy zvolit orchestraci nad více modely. Tento praktický průvodce vysvětluje klíčové koncepty (stav, uzly, hrany, podmíněné větvení, paralelismus), návrhové vzory multi-agentních workflow, observabilitu, bezpečnost a řízení nákladů. Najdete zde i rozhodovací matice, checklisty a referenční architekturu pro produkční nasazení. Obsah Proč LangGraph a proč teď Základní koncepty LangGraphu Single-agent vs. multi-agent: kdy který přístup Orchestraci nad více …
LangGraph a agent orchestrace: nový standard pro AI agenty Číst dál