Retrieval-Augmented Generation (RAG) je nejspolehlivější způsob, jak dostat velké jazykové modely (LLM) do podnikové praxe: odpovídají jen z interních zdrojů, dávají citace a dají se auditovat. O tom, zda budou odpovědi přesné a ekonomicky udržitelné, ale rozhoduje kvalita datové pipeline – od ingesce a extrakce, přes chytrý chunking a embeddings, až po hybridní retrieval, re-ranking, evaluaci, governance a provozní monitoring. Tento rozsáhlý, SEO-optimalizovaný průvodce jde do hloubky a ukazuje, jak navrhnout pipeline, která se škáluje od stovek dokumentů po miliony pasáží, drží náklady pod kontrolou a prokáže kvalitu čísly, ne dojmy.
Proč se vyplatí investovat do datové pipeline pro RAG
Samotné LLM bez přístupu k vašim zdrojům odpovídá „z hlavy“ a nemůže citovat – to je problém pro přesnost i compliance. RAG naopak odděluje fakta od chování: dokumenty a tabulky zůstávají ve vašem úložišti, retriever je najde a předá do promptu, generátor vytvoří odpověď s citacemi. Klíčová je proto kvalita retrievalu a přípravy dokumentů. Špatný chunking, slabý embedding nebo duplicate-noise spolehlivě rozboří i nejlepší model.
Investice do pipeline přináší tři zřejmé benefity: (1) rychlé aktualizace znalostí bez re-tréninku (reindex místo fine-tune), (2) auditovatelnost a důvěru (citace, lineage, „as-of“ evaluace), (3) predikovatelné náklady a výkon (budget kontextu, cache, hybridní retrieval). Výsledek: méně halucinací, vyšší přesnost, nižší latence a lepší přijetí uživateli.
Referenční architektura: od zdrojů k odpovědi s citacemi
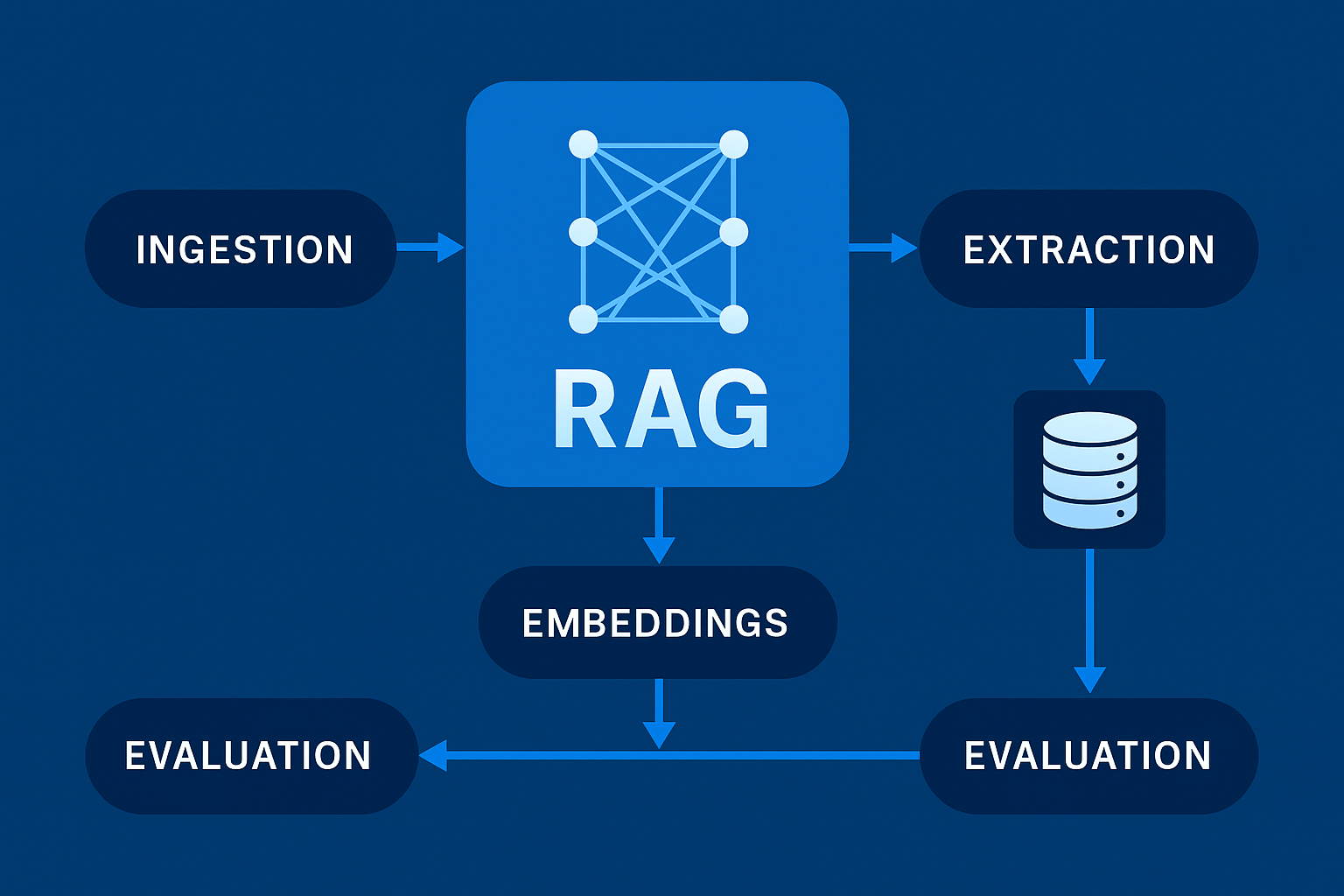
Odolná architektura RAG se skládá z jasných vrstev, které lze samostatně měnit a škálovat:
- Zdrojová vrstva – DMS, wiki, CRM, ticketing, sdílené disky, e-maily, web, databáze, tabulky, obrázky.
- Ingestion – konektory (dávky, webhooky, CDC), právní filtry, verzování a evidence původu.
- Extrakce a normalizace – OCR, parsing, čištění boilerplate, deduplikace, jazyk, PII redakce.
- Chunking – segmentace textu na smysluplné pasáže s overlapem, identitou a metadaty.
- Embeddings – výpočet vektorů, verze embedding modelu, normalizace, komprese.
- Indexace – vektorový (HNSW/IVF-PQ) + lexikální (BM25), filtry, časová platnost.
- Retrieval orchestrace – hybridní dotazy, re-ranking, MMR, komprese kontextu.
- Generace – konstrukce promptu, citace, guardraily, post-processing, validace formátu.
- Evaluace a observabilita – metriky retrievalu a odpovědí, drift, náklady, audit.
Ingestion: konektory, změnové toky a verzování
Smyslem ingestion je bezpečně a predikovatelně dostat obsah tam, kde ho lze extrahovat a indexovat. Praktické zásady:
- Režim aktualizací: kombinujte dávky (noční joby) a near-real-time (webhooky, CDC). Důležité dokumenty musí být v indexu během minut, ne dní.
- Práva a citlivost: už v této vrstvě označte citlivé kolekce (PII/PHI, obchodní tajemství) a přenášejte je s RBAC tagy; ušetříte si pozdější migrace.
- Verzování: žádný přepis. Každá změna je nová verze s timestampem, autorem a původem. Umožní to „as-of“ evaluace a audit.
- Evidence původu: zdroj, cesta, hash obsahu. Hodí se při sporech o aktuálnost a při forenzice.
Extrakce obsahu: PDF, Office, HTML, e-maily, obrázky a OCR
Extrakce je první místo, kde se dá hodně pokazit i napravit. Doporučení podle typu:
- PDF a skeny: používejte OCR s detekcí tabulek a vícesloupcových layoutů; ukládejte i souřadnice textu pro přesné citace a náhledy stránek. Odstraňte vodoznaky a skryté vrstvy, které matou tokenizaci.
- DOCX/PPTX/XLSX: extrahujte text, ale také strukturu (nadpisy, seznamy, tabulky, poznámky). Tabulky ukládejte paralelně jako „table-chunks“ s CSV-like reprezentací.
- HTML/wiki: čistěte navigační šablony, patičky a reklamy; zachovejte breadcrumbs a interní odkazy jako metadata pro boosting relevance.
- E-maily/chat: rozlišujte citované části, vlákna, přílohy a účastníky; timestamp je kritický pro časové filtry.
- Obrázky a diagramy: vedle OCR ukládejte popisek a klíčové entity (např. čísla parametrů). Pokud obrázky nesou klíčové informace (schémata), vytvořte cross-link na relevantní textové pasáže.
Udržujte kopii „kanonické“ extrakce i surového zdroje. Tím umožníte vylepšit extraktory zpětně a re-indexovat bez opakovaného ingestion.
Normalizace, deduplikace a obohacení metadaty
Cílem je odstranit šum, snížit redundanci a přidat informace, které usnadní filtrování i boosting:
- Deduplikace: fuzzy hash a „near-duplicate“ detekce, abyste neplnili index kopiemi téhož PDF s jiným názvem.
- Jazyk a skript: jazyk dokumentu i chunku; u vícejazyčných sbírek je to nezbytné pro správný embedding i routing dotazu.
- Boilerplate stripping: pryč s navigací, patičkami a šablonovými hlavičkami, které by se jinak embedovaly pořád dokola.
- Metadata: autor, oddělení, verze, datum, produkt, jurisdikce, klasifikace citlivosti, přístupová práva. Metadata umožní hybridní dotazy „jen verze ≥ v3 a jen CZ“.
- PII redakce: redigujte citlivé údaje už v této vrstvě; do embeddingů neposílejte víc, než je nutné.
Chunking do hloubky: strategie, velikosti, identita a bezpečnost
Chunking rozhoduje, co se nakonec dostane do promptu. Špatný chunking = ztracený kontext nebo naopak dlouhé a málo relevantní pasáže. Osvědčené přístupy:
Strategie chunkingu
- Pravidlový (token-based) s overlapem: jednoduchý a univerzální; dejte si pozor na trhání vět a tabulek. Overlap 10–20 % tlumí „useknuté“ myšlenky.
- Hierarchický (recursive): napřed kapitoly a nadpisy, pak odstavce, až nakonec délka; drží význam lépe u manuálů a právních textů.
- Sémantický: detekuje přirozené hranice témat; hodí se pro zápisy z meetingů, FAQ a volný text.
Velikosti a překryvy
| Obsah | Typická velikost (tokeny) | Overlap | Poznámka |
|---|---|---|---|
| Právní/technické manuály | 400–800 | 15–20 % | Hierarchický, zachovat čísla sekcí |
| FAQ a KB | 200–400 | 10–15 % | Jednotka dotaz-odpověď |
| Tabulky/specifikace | 100–300 | 5–10 % | „Table-chunks“ s vlastními indexy |
| E-maily/zápisy | 300–600 | 10–20 % | Respektovat vlákna a čas |
Identita a citace
Každý chunk musí nést canonical_id (dokument#sekce#offset), breadcrumbs (cesta v dokumentu), position (pořadí) a permissions (RBAC). Jen tak lze zpětně vytvořit klikatelné citace a udržet bezpečnost. Pro PDF uchovávejte i čísla stran a bounding boxy; citace pak mohou odkazovat přesně na stránku a odstavec.
Embeddings: volba modelu, dimenze, vícejazyčnost a verze
Embeddingy převádějí text na vektory; kvalita retrievalu na nich stojí. Co řešit:
- Jazyk: pro češtinu a smíšené kolekce volte multilingvní nebo lokálně adaptované embeddingy. U vysoce odborných domén pomůže doménová adaptace.
- Dimenze a normalizace: vyšší dimenze mají lepší separaci, ale stojí víc RAM. Vektory L2-normalizujte (stabilnější kosinová podobnost).
- Kompresní techniky: produktové kvantování (PQ) a „IVF-PQ“ dramaticky šetří paměť; pro nejpoužívanější kolekce držte „hot tier“ bez komprese.
- Pooling: u delších pasáží dávejte pozor na průměrování; klíčová slova nebo čerstvé pasáže lze vážit víc.
- Verzování: měňte embedding_version při každé významné změně modelu; umožníte postupný re-embed a srovnání metrik před/po.
| Volba | Výhoda | Trade-off |
|---|---|---|
| Vysoce dimenzní embedding | Skvělá separace podobností | Vyšší RAM a pomalejší indexace |
| Multilingvní embedding | Vícejazyčné kolekce „z krabice“ | Nižší přesnost než monolingvní |
| IVF-PQ index | Výrazně menší spotřeba | Drobná ztráta přesnosti |
| HNSW index | Rychlé a přesné dotazy | Vyšší paměť, delší build |
Indexace a vyhledávání: vektor, BM25, hybrid a re-ranking
Čistě vektorový přístup ztrácí sílu tam, kde rozhodují přesné termíny, kódy, citace paragrafů. Nejjistější je hybridní retrieval – kombinace BM25 a dense vyhledávání s následným fúzováním pořadí a re-rankingem:
- Vektorový index: HNSW pro rychlost a kvalitu, IVF-PQ pro úsporu. Parametry (M, efConstruction, efSearch) měňte s ohledem na Recall a latenci.
- BM25: výborný na pojmenované entity, kódy, přesné znění. Udržujte čistý text bez boilerplate, jinak BM25 šumí.
- Fúze výsledků: Reciprocal Rank Fusion je robustní jednoduchý baseline, na top N pak nasadíte re-ranking.
- Re-ranking: cross-encoder přesněji zhodnotí relevanci páru dotaz–pasáž; používejte na 20–100 kandidátů.
- Filtry a boosting: metadata (jazyk, verze, produkt, jurisdikce), časová platnost a „time-decay“ pro čerstvé dokumenty.
- MMR: Maximal Marginal Relevance snižuje redundanci; do promptu vložíte rozmanité, ne duplicity.
Orchestrace dotazu: query rewrite, MMR, komprese kontextu a citace
To, jak dotaz připravíte, má obrovský dopad na kvalitu i cenu:
- Query understanding: detekce jazyka, záměru, pravopisu, entit, verze produktu; složité dotazy rozložte na subdotazy (multi-hop).
- Query rewrite: rozšíření o synonyma a interní terminologii; pro vícejazyčné prostředí překlad dotazu → retrieval → zpětný překlad odpovědi.
- Context compression: u dlouhých pasáží nejdříve vytvořte „focused“ shrnutí se zachováním klíčových faktů a citací, teprve potom vkládejte do promptu.
- Prompt konstrukce: jasná role, formát odpovědi (např. strukturované sekce), pravidla citací (ID chunku, stránka, verze), chování při nedostatku informací.
Generace odpovědi: formát, věrnost, fallbacky a post-processing
Generátor má dvě povinnosti: držet se zdrojů a vrátit výsledek ve sjednaném formátu. Praktiky, které fungují:
- Věrnost ke zdrojům: zaveďte pravidlo, že tvrzení mimo citace je chyba. U odpovědí vyžadujte vždy seznam citovaných chunků a verzi dokumentu.
- Fallbacky: když retriever nic nenašel, odpověď musí bezpečně přiznat „nedostatek informací“ a nabídnout eskalaci (např. komu napsat).
- Post-processing: kontrola formátu (JSON/sekce), deduplikace citací, kontrola jazykové konzistence, validace odkazů na stránky.
Evaluace kvality: retrieval vs. odpověď, offline i online
Bez měření se debata vrací k dojmům. Evaluace musí rozlišit retrieval a odpověď:
Metriky retrievalu
- Recall@k: podíl dotazů, kde je některý „gold“ dokument v top k kandidátech.
- MRR a nDCG: zohledňují pořadí relevantních pasáží a více úrovní relevance.
- Coverage: kolik kolekce je „dosažitelné“; odhalí sirotky bez kvalitních embeddingů.
Metriky odpovědi
- Exact match/F1: pro faktografické otázky.
- Faithfulness: podíl tvrzení podložených citacemi; penalizace za halucinace.
- Hallucination rate: frekvence nepravdivých či necitovaných tvrzení.
- Lidské hodnocení: dvojitě slepé posudky užitečnosti a srozumitelnosti.
Eval sadu držte as-of: u každého příkladu uložte datum, verzi dokumentů a gold citace. Každá změna chunkingu, embeddingu či re-rankeru musí projít regresním testem. Online nasazení doplňte A/B testy a sledujte byznys KPI (čas do odpovědi, míra eskalací, NPS).
Monitoring a observabilita: drift, latence, náklady, SLA
RAG je živý systém – dokumenty se mění, dotazy kolísají, indexy stárnou. Co sledovat:
- Retrieval kvalita v čase: Recall@k, MRR, podíl „no sufficient context“; alerty při propadu.
- Latence podle etap: ingestion → retrieval → re-ranking → konstrukce promptu → generace → post-processing; identifikujte úzká hrdla.
- Náklady: tokeny za kontext a odpověď, re-ranker, OCR, rebuild indexů; limity a budgety.
- Drift dat a dotazů: nové typy dokumentů, změna jazyka/terminologie; automatický re-embed a re-index.
- Dostupnost a zdraví indexů: velikost, fragmentace, stav konektorů a front.
Governance a bezpečnost: PII, RBAC/ABAC, lineage a audit
RAG často pracuje s citlivými zdroji. Governance není „nice to have“, ale povinnost:
- RBAC/ABAC: přístup ke chunkům je filtrován podle role a atributů uživatele; nikdy nevkládejte do promptu, co uživatel nemá vidět.
- PII/PHI redakce a minimalizace: citlivá data maskujte v ingestu; logy držte bez PII.
- Lineage: dokument → verze → chunk → embedding_version → index_version; jen tak vysvětlíte, proč a z čeho vznikla daná odpověď.
- Audit logy a evidence pack: kdo dotazoval, co bylo vráceno, které citace, jaká verze modelu; připravené balíčky pro interní/externí audit.
- Data residency a šifrování: šifrujte za klidu i při přenosu; respektujte regiony a smluvní závazky.
Výkon a náklady: cache, komprese, inkrementální update
Škálování RAG je z velké části o chytré ekonomice:
- Response cache: cache pro opakující se dotazy; invalidujte při změně relevantních kolekcí.
- Embedding cache: nepočítejte stejné chunky znovu; hlídejte etag/hashe obsahu.
- Index komprese: IVF-PQ, kvantizace; „hot tier“ bez komprese pro nejčastěji dotazované sbírky.
- Inkrementální re-embed: při změně modelu nebo chunkingu přepočítávejte jen dotčené části, ne vše.
- Budget kontextu: po re-ranku a MMR vložte jen pasáže s jasnou přidanou hodnotou; šetříte tokeny i latenci.
LLMops v praxi: verze, release, evidence pack a runbooky
Produkční RAG bez LLMops dlouho nevydrží. Zaveďte:
- Registr modelů a indexů: verze embeddingů, re-rankerů, parametrů indexu; rollback postupy.
- Verzování promptů a kolekcí: prompty jako kód, testy, linting; kolekce s datem a zdrojem.
- Release brány: regresní eval, bezpečnostní kontrola, schválení vlastníkem kolekce.
- Runbooky a incident management: co dělat při výpadku retrieveru, poškozeném indexu, nárůstu halucinací.
Blueprinty pro nejčastější use-cases
Podnikový znalostní asistent
Obsah: wiki, SOP, ticketing KB, interní směrnice. Chunking: hierarchicky 300–600 tokenů, 15 % overlap. Embeddings: multilingvní. Retrieval: hybrid BM25+dense, re-ranking top 50, MMR. Citace: klikatelné s verzí. Eval: Recall@50 ≥ 0,9; faithfulness ≥ 0,95; NPS ≥ 4/5.
Právní a compliance RAG
Obsah: šablony smluv, playbooky, DPA, metodiky. Chunking: sekce/odstavce 400–800 tokenů, tabulky zvlášť. Filtry: jurisdikce, verze dokumentu. Re-ranking povinně. Governance: RBAC, audit logy, PII maskování. Odpovědi pouze se zdroji a čísly paragrafů.
Technická dokumentace a podpora
Obsah: manuály, release notes, issue tracker, komunitní fóra. Hybrid s time-decay pro preferenci nových verzí. Query rewrite extrahuje verzi produktu ze vstupu. KPI: snížení času „time-to-first-answer“ a počtu eskalací.
Sales enablement a produktová fakta
Obsah: datasheety, price-listy, obchodní podmínky. Tabulky držte v separátní kolekci a napojujte jako strukturované odpovědi. Striktní citace a verze dokumentu; při neaktuálnosti odpověď odmítne a odkáže na správce obsahu.
Pokročilá témata: multimodální, strukturovaný a multi-hop RAG
- Multimodální RAG: vedle textu indexujte obrázky a diagramy; dotaz lze vektorizovat z textu i z náhledů. Citace pak odkazují na stránku a bounding box.
- Strukturovaný RAG: kombinace dokumentů s databázemi/SQL a grafy; retriever vrací nejen pasáže, ale i dotázaná data (tool-use).
- Multi-hop dotazy: orchestrátor rozloží dotaz na více kroků (najdi definici → najdi výjimku → porovnej); kontext z předchozích kroků se ukládá do krátkodobé paměti.
- Learning-to-rank: učte re-ranker na klik-logách a lidských preferencích; přesnost retrievalu tím dlouhodobě roste.
Roadmapa adopce: pilot → rozšíření → škálování
Pilot (4–8 týdnů)
- Jedna priorita (např. KB) a dvě kolekce. Základní ingestion, extrakce, hierarchický chunking, multilingvní embeddingy, hybridní retrieval.
- MVP s citacemi a měřením Recall@50, MRR, faithfulness; uživatelské NPS.
Rozšíření (2–3 měsíce)
- Přidat re-ranking, MMR, context compression; RBAC a PII redakci; audit logy; „as-of“ eval pipeline.
- Optimalizovat náklady (cache, komprese indexu, budget kontextu) a latenci.
Škálování (6–12 měsíců)
- Více jazyků, právní kolekce, multi-tenant, integrace do chatu a BI, model/embedding registry, drift monitoring, evidence pack pro audit.
Antipatterny a časté chyby
- Spoléhat na „velký model“ bez retrievalu: bez zdrojů budou odpovědi zastarávat a nepůjdou auditovat.
- Špatný chunking: příliš malé či velké pasáže, žádný overlap, žádné identity a stránky – citace pak nejsou přesné.
- Monolitický přístup: bez hybridního vyhledávání přijdete o přesné termíny a kódy; bez re-rankeru o jemnou relevanci.
- Bez „as-of“ evaluace: backtest na „umytých“ datech vypadá krásně, ale v produkci selže.
- Nedostatečná governance: chybějící RBAC, lineage a audit logy; to je bezpečnostní a reputační riziko.
- Ignorování nákladů: dlouhé prompty a zbytečný kontext dramaticky prodraží inference; bez cache a komprese neškálujete.
Závěr: RAG jako spolehlivá paměť organizace
Silná datová pipeline dělá z RAG nástroj, kterému mohou uživatelé i auditoři věřit. Když zvládnete kvalitní ingestion a extrakci, chytrý chunking, vhodné embeddingy, hybridní retrieval s re-rankingem a důslednou evaluaci, získáte systém, který je přesný, rychlý a ekonomicky udržitelný. Governance a observabilita zaručí, že RAG obstojí i při změnách obsahu, růstu dotazů a nárocích na bezpečnost. Začněte pilotem, měřte vše podstatné, iterujte a škálujte – a proměníte volně plynoucí firemní znalosti v ostré odpovědi, které se dají citovat, auditovat a opakovaně spolehnout.