Embeddings (vektorové reprezentace textu) jsou tichým motorem moderních AI aplikací. Od vyhledávání podobných dokumentů přes RAG (Retrieval-Augmented Generation) až po deduplikace a doporučování – kvalita vektorových reprezentací často rozhoduje víc než volba samotného LLM. Tento rozsáhlý, SEO-optimalizovaný průvodce ukazuje, jak vybrat správný embedding model pro češtinu i vícejazyčné prostředí, jak jej správně hodnotit (Recall@k, nDCG, MRR, faithfulness) a jak přemýšlet o nákladech, latenci a provozní udržitelnosti. Dostanete konkrétní blueprinty, metodiku evaluace „as-of“ i praktické tipy pro indexaci (HNSW, IVF-PQ), chunking a governance.
Co jsou embeddings a proč na nich záleží
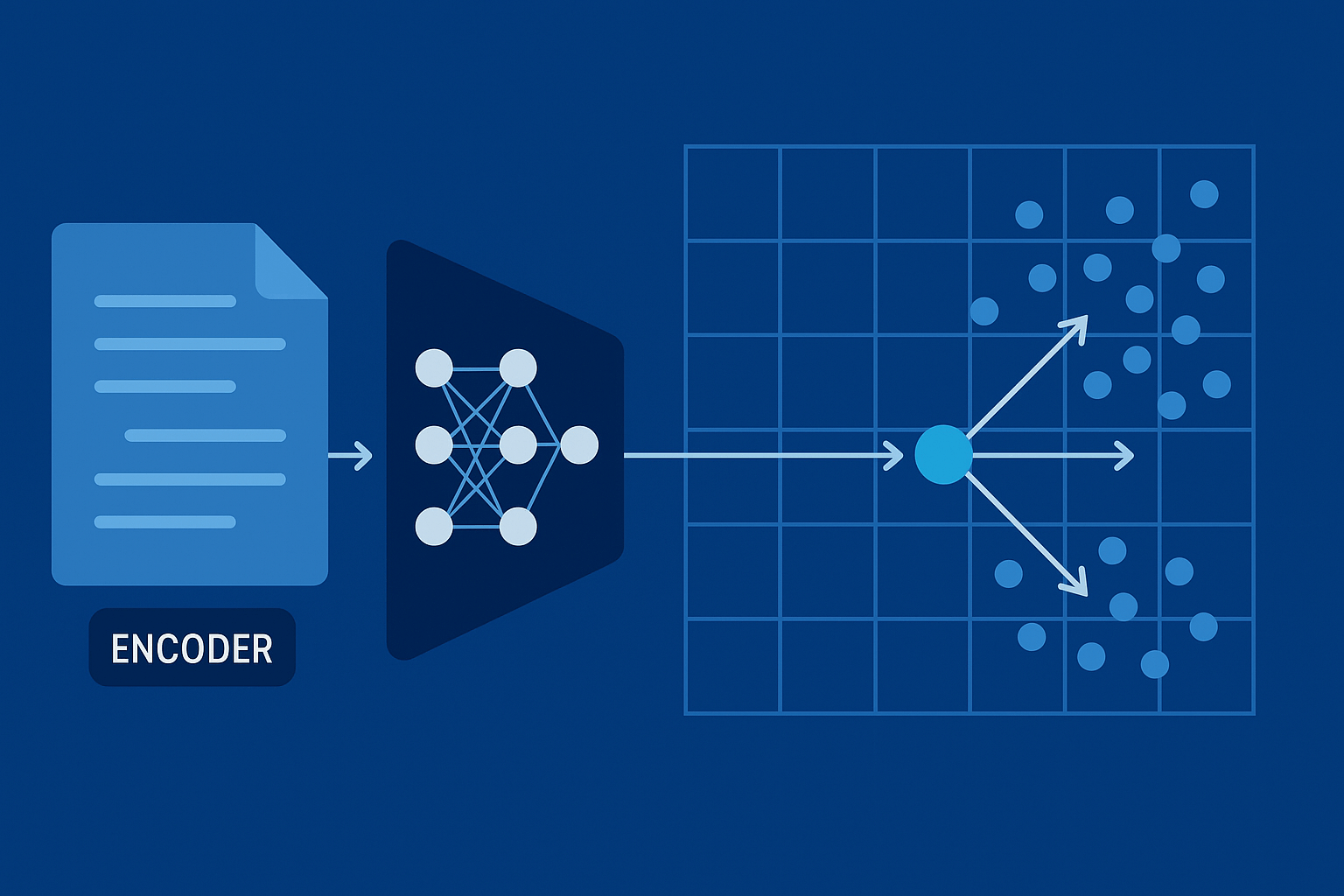
Embedding převádí vstup (větu, odstavec, dokument, dotaz) na vektor reálných čísel tak, aby semanticky podobné texty byly „blízko“ a rozdílné „daleko“ podle zvolené metriky (nejčastěji kosinová podobnost). Kvalitní embedding je takový, který:
- drž í intuitivní topologii (synonyma a parafráze blízko, nesouvisející text daleko),
- je robustní ke šumu (diakritika, překlepy, lehká změna slovosledu),
- respektuje jazyk a doménu (právní, medicína, technika),
- je stabilní napříč korpusy a zároveň levný/rychlý při dotazování.
V praxi to znamená vyšší přesnost vyhledávání, lepší citace v RAG a nižší halucinace LLM, protože do kontextu dostanete správné pasáže. Špatný embedding = špatné zdroje v promptu = horší odpověď, a to bez ohledu na kvalitu samotného LLM.
Kdy embeddings používáte: typické use-cases
- RAG a podnikové vyhledávání: vybrat nejrelevantnější pasáže pro LLM a dodat je s citacemi.
- Semantické vyhledávání: najít podobné dokumenty i bez přesných klíčových slov (synonyma, parafráze).
- Klasifikace a směrování: přiřazení ticketů na správný tým, směrování e-mailů, intent detection.
- Klastrování a deduplikace: skupinování podobných článků, detekce near-duplicate, „samoservis“ taxonomie.
- Rekomendace: „podobné produkty/články“; kombinace s explicitními signály kliků a nákupů.
- Metadatové obohacení: vyhledání definic, citace, automatické linkování mezi dokumenty.
Specifika češtiny (a dalších jazyků CEE) pro embeddings
Čeština je flektivní jazyk s bohatou morfologií, volným slovosledem a diakritikou. To má praktické důsledky:
- Morfologické varianty: „účet“, „účtu“, „účtem“ – model musí chápat, že jde o jeden pojem v různých pádech.
- Diakritika: uživatelé často píší bez diakritiky; dobrý embedding by měl být tolerantní (normalizace vstupu je nutnost).
- Slovosled: „fakturuje se DPH“ vs. „DPH se fakturuje“ – reprezentace by měla zůstat blízká.
- Doménové termíny a zkratky: „přiznání k DPH“, „ZDPH“, „EET“, „DPPO“; multilingvní modely je nemusí znát bez adaptace.
Pro české a vícejazyčné prostředí proto často vítězí multilingvní embeddings nebo lokálně adaptované modely s dobrým pokrytím češtiny a okolních jazyků (SK, PL, DE). Pokud obsluha dotazů běží v češtině a zdroje jsou převážně česky, zvažte i monolingvní CZ model – bývá menší, rychlejší a přesnější v rámci jazyka. Pro cross-lingual (dotaz EN, dokument CZ) je naopak výhodou multilingvní trénink.
Typy embedding modelů a jejich rozdíly
V praxi potkáte tři velké rodiny modelů. Rozdíly shrnuje tabulka; konkrétní názvy se rychle vyvíjejí, důležité jsou principy.
| Typ | Charakteristika | Výhody | Limity | Typické použití |
|---|---|---|---|---|
| Monolingvní (CZ) | Trénink na českých datech, optimalizace pro lokální jazykové jevy | Vyšší přesnost v češtině, menší model, nižší latence | Slabší cross-lingual, nutnost řešit jiné jazyky separátně | RAG a search v čistě českém portfoliu (právo, veřejná správa, média) |
| Multilingvní | Podpora desítek jazyků v jednom prostoru | Cross-lingual vyhledávání, jednotná správa indexu | Obvykle o chlup nižší přesnost v jednotlivém jazyce | Mezinárodní firmy, CZ/EN dokumentace, cross-border týmy |
| Doménově adaptované | Dotrénované na párech dotaz↔pasáž ve vaší oblasti | Vysoká relevance v oboru, robustní terminologie | Nutnost dat a evaluace, riziko overfittingu | Právo, zdravotnictví, finance, telco, průmysl |
Kromě jazykové podpory sledujte dimenzi vektoru (256–1024+), pooling (CLS, mean pooling, weighted pooling), normalizaci (L2) a licenci (komerční využití, redistribuce). Větší dimenze často zlepšuje separaci, ale zvyšuje paměť a čas indexace. Mean pooling bývá stabilní baseline, ale u dlouhých pasáží pomáhá „salience-aware“ nebo hierarchické poolingy.
Kritéria výběru: kvalita, latence, paměť, licence, governance
- Kvalita/relevance: Recall@k, nDCG, MRR na vašem korpusu. Bez vlastního testu nevybírejte.
- Jazyk a doména: čeština a související jazyky, zvládání diakritiky a morfologie; model se slovníkem vašeho oboru.
- Latence a throughput: v reálném provozu (CPU/GPU), včetně doby re-rankingu a filtrů.
- Paměť a velikost indexu: dimenze × počet chunků × režie indexu; plán „hot/cold“ tierů.
- Licence a T&C: komerční použití, data usage policy, on-prem vs. cloud.
- Bezpečnost a governance: PII, RBAC, logging, reprodukovatelnost; „evidence pack“ pro audit.
- Ekonomika a udržitelnost: náklady na embedding (výpočet) + uložení + dotazy; možnost komprese (IVF-PQ) a cache.
Metodika evaluace: dataset, „as-of“ přístup a metriky
Abyste porovnali embeddingy fér, potřebujete reprezentativní dataset a stabilní metodiku:
- Gold sada dotazů: 100–1000 reálných dotazů v jazycích, které očekáváte (CZ/EN). U každého dotazu uveďte 1–5 „gold“ pasáží (ground truth).
- As-of snapshot: zamrazte kolekci dokumentů; evalujte proti stavu, který byl znám v daný čas, jinak si nechtěně „vylepšíte“ výsledky.
- Blind test: pokud ručně hodnotíte, hodnotitelé nesmí znát, z kterého modelu výsledek pochází.
- Jednotné parametry: stejné chunking, filtry, re-ranking a K; jinak porovnáváte pipeline, ne embedding.
- Report: kromě metrik logujte top chybové případy (dotazy bez relevantního výsledku, časté omyly, jazykové problémy).
Retrieval metriky v praxi: Recall@k, nDCG, MRR, Coverage
Recall@k říká, v kolika případech je „gold“ pasáž mezi prvními k kandidáty. Je to nejpraktičtější metrika pro RAG, protože re-ranker a LLM obvykle pracují jen s top N pasážemi. nDCG (normalized Discounted Cumulative Gain) zohledňuje pozici a víc úrovní relevance – lepší pro vyhledávání, kde záleží, zda je relevantní pasáž první nebo pátá. MRR (Mean Reciprocal Rank) je zjednodušené měřítko „jak vysoko“ se první relevantní pasáž objevuje. Coverage sleduje, jaká část kolekce je „dosažitelná“ – odhalí „sirotky“ bez kvalitních embeddingů (např. tabulky bez textu).
U RAG navíc sledujte faithfulness a hallucination rate na úrovni odpovědi: kolik tvrzení je přímo podložených citovanými pasážemi a kolik výroků model přidal „z hlavy“.
Online metriky a A/B testy: co měřit v produkci
- Time-to-first-relevant: jak rychle se najde první relevantní pasáž; dobré pro UX.
- Share of answers with citations: podíl odpovědí s minimálně jednou kvalitní citací.
- Click-through na citace: indikátor důvěry a užitečnosti zdrojů.
- Re-prompt rate / eskalace: kolik dotazů uživatel musí přeformulovat nebo eskalovat.
- Náklady na dotaz: tokeny kontextu + cena re-rankeru; porovnávejte mezi variantami.
A/B testujte embeddingy se stejným retrieverem a re-rankerem; jen tak zjistíte čistý přínos vektoru. U RAG sledujte i konverzní KPI (vyřešené tickety, zkrácení času podpory, snížení OOS ve vyhledávání atd.).
ANN indexy a vyhledávání: HNSW vs. IVF-PQ, hybrid s BM25
Embedding bez správného indexu daleko nedojde. V produkci se osvědčují dvě hlavní strategie:
HNSW (Hierarchical Navigable Small World)
Rychlé dotazy, vysoká přesnost, větší paměť. Vhodné pro „hot“ kolekce s přísnými SLA. Klíčové parametry jsou M (stupeň grafu) a efConstruction/efSearch (kompromis mezi rychlostí a přesností).
IVF-PQ (Inverted File + Product Quantization)
Škálovatelné a paměťově úsporné. Vhodné pro obrovské sbírky a „cold“ tier. O něco nižší přesnost, kterou doženete re-rankingem a MMR. Při správném nastavení dokáže dramaticky snížit RAM/Disk bez zásadní ztráty kvality.
Hybrid s BM25
Lexikální vyhledávání (BM25) doplňuje sémantiku tam, kde rozhodují přesné termíny, kódy a citace. Reciprocal Rank Fusion je robustní způsob, jak zkombinovat pořadí a získat to nejlepší z obou světů. Na top N kandidátů pak aplikujte cross-encoder re-ranker, který jemněji posoudí relevanci.
Chunking a metadata: proč často rozhodnou víc než model
Špatně rozsekaný dokument zničí i dobrý embedding. Doporučení:
- Hierarchický chunking: nejdřív sekce/nadpisy, pak odstavce, až nakonec délka (např. 300–600 tokenů) s 10–20 % overlapem.
- Table-chunks: tabulky ukládejte zvlášť (CSV-like text + metadata); lexikální složka vyhledávání a re-ranker pak lépe pochopí hlavičky a hodnoty.
- Identita a citace: canonical_id, breadcrumbs, číslo strany, bounding box; bez toho nelze stavět auditovatelné citace.
- Metadata pro filtry: jazyk, verze, produkt, jurisdikce, platnost; zlepší relevanci a bezpečnost (RBAC/ABAC).
Tip: často se vyplatí krátká context compression – před vložením do promptu pasáž „zhušťte“ na několik hutných vět s ponecháním citace.
Multilingvní scénáře: router, překlad vs. multilingvní embeddings
V mezinárodních firmách jsou dotazy i zdroje vícejazyčné. Tři osvědčené vzory:
- Multilingvní embeddingy v jednom prostoru: jednoduchá správa, cross-lingual search funguje „z krabice“. Mírně nižší přesnost v jednotlivých jazycích kompenzujte re-rankerem.
- Jazykový router: detekujte jazyk dotazu i dokumentu a posílejte do jazykově specifického indexu. Vyšší přesnost, ale více operativy.
- Překlad dotazu nebo dokumentů: překlad dotazu do jazyka dokumentů (rychlé) nebo překlad dokumentů do pivot jazyka (nákladné, pozor na drift). Hodí se výjimečně.
Pro češtinu bývá nejlepší volbou multilingvní embeddings s dobrou podporou češtiny a přísným re-rankerem; pro čistě české korpusy je skvělý monolingvní model.
Doménová adaptace: jak přizpůsobit embeddingy vaší oblasti
Pokud pracujete v úzce specializované oblasti (právo, medicína, finance, telco), generický embedding často nestačí. Co funguje:
- Kontrastivní dotrénování: páry dotaz↔pasáž, „hard negatives“ z podobných, ale nesprávných pasáží.
- Adaptery/LoRA: lehké vrstvy, které se dají zapínat/vypínat podle domény; menší compute, rychlejší iterace.
- Kurátorství dat: kvalita překoná kvantitu. Raději 10 000 precizních párů než 100 000 šumových.
- Eval po každé iteraci: zlepšení na dev setu musí potvrdit blind test na hold-outu.
Výsledek testujte nejen na Recall@k, ale i na stability (výsledky napříč styly dotazů) a robustnosti (překlepy, diakritika, slang, zkratky).
Náklady a TCO: výpočet, paměť, indexace, latence a cache
Ekonomiku embeddings určují tři položky: výpočet embeddingů, úložiště/index a dotazy.
Výpočet embeddingů
Jednorázová fáze (při ingestu) + průběžné updaty. U menších modelů lze běžet na CPU, ale pro vyšší throughput a re-embed velkých kolekcí využijete GPU. Pomáhá embedding cache (re-embed jen při změně obsahu nebo verze modelu).
Úložiště a index
Velikost roste lineárně s počtem chunků a dimenzí. U extrémních kolekcí nasazujte IVF-PQ, „hot tier“ držte jako HNSW. Pravidelná re-indexace a defragmentace udržují latenci.
Dotazy a latence
Celková latence = detekce záměru → retrieval → re-ranker → konstrukce promptu → LLM. Optimalizujte K (počet kandidátů), MMR (méně redundance), context budgeting (jen to, co má přidanou hodnotu) a response cache pro opakující se dotazy. Hybrid s BM25 často sníží potřebu stahovat „padesát podobných pasáží“.
Governance a bezpečnost: PII, RBAC/ABAC, versioning, audit
Vektorový vyhledávač pracuje s citlivým obsahem. Bezpečnostní a regulatorní požadavky proto přeneste přímo do pipeline:
- PII/PHI redakce a minimalizace: maskujte citlivé údaje už při ingestu; do embeddingu neposílejte víc, než je nutné.
- RBAC/ABAC: chunk nese oprávnění; filtry aplikujte už při retrievu, ne až po.
- Versioning a lineage: dokument → verze → chunk → embedding_version → index_version; reprodukovatelnost je podmínkou auditu.
- Audit logy: kdo co vyhledal, jaké pasáže se dostaly do promptu; nezbytné pro forenziku i zlepšování kvality.
Blueprinty: právní RAG, produktové vyhledávání, interní KB
Právní RAG (CZ/EN)
Korpus: šablony smluv, playbooky, zákonné citace, rozhodnutí. Chunking: sekce a odstavce, 400–800 tokenů, 15–20 % overlap, tabulky zvlášť. Embeddings: multilingvní s doménovým adapterem. Retrieval: hybrid s přísnými filtry na jurisdikci a verzi. Re-ranker: povinně. Metriky: Recall@50 ≥ 0,9, faithfulness ≥ 0,95, lidské právní review jako brána do produkce.
Produktové vyhledávání (e-shop, CZ/EN/DE)
Korpus: názvy, popisy, parametry, recenze, Q&A. Chunking: tabulky parametrů do separátní kolekce; text 200–400 tokenů. Embeddings: multilingvní; jazykový router pro specifické trhy. Retrieval: hybrid s BM25 pro přesné parametry a kódy. Re-ranker: učte na klik-logách (learning-to-rank). KPI: CTR, konverze, coverage long-tail dotazů.
Interní znalostní báze (HR/IT/Procurement)
Korpus: wiki, SOP, ticketing KB. Chunking: 300–600 tokenů, 10–15 % overlap, identita pro citace. Embeddings: multilingvní nebo CZ monolingvní. Retrieval: hybrid, time-decay preferuje novější články. Metriky: Recall@50, MRR, snížení eskalací a času na vyřešení ticketu.
Antipatterny a troubleshooting
- Sázet vše na „větší model“: špatný chunking a bez BM25 vám větší embedding nezachrání.
- Ignorovat češtinu: model bez dobrého CZ pokrytí selže na diakritice a morfologii; normalizujte vstup a testujte CZ dotazy.
- Přetěžovat kontext: do promptu cpát desítky podobných pasáží zvyšuje cenu a zhoršuje kvalitu; použijte MMR a context compression.
- Žádná „as-of“ evaluace: bez zamraženého snapshotu si nechtěně vylepšíte výsledky a v produkci zklamete.
- Bez governance: chybějící RBAC a audit logy jsou bezpečnostní i reputační riziko.
- Zapomenuté tabulky: čísla a parametry vyžadují zvláštní zacházení; jinak BM25 a re-ranker nemají co chytit.
- Špatný threshold podobnosti: příliš nízký vrací šum, příliš vysoký „umlčí“ výsledky; ladit podle ROC/PR křivky a nákladů chyb.
Roadmapa zavedení: pilot → rozšíření → škálování
Pilot (4–8 týdnů)
- Definujte use-case (např. interní KB) a metriky (Recall@50, faithfulness, NPS).
- Postavte ingestion, extrakci, hierarchický chunking a hybridní retrieval s re-rankerem.
- Otestujte 2–3 embeddingy na stejné pipeline a rozhodněte na základě metrik + chybových případů.
Rozšíření (2–3 měsíce)
- Zapněte RBAC/ABAC, audit logy, „as-of“ eval pipeline a monitoring driftu.
- Optimalizujte náklady (IVF-PQ pro „cold“ tier, response/embedding cache, context budgeting).
- Začněte učení re-rankeru na klik-logách; zaveďte A/B testy.
Škálování (6–12 měsíců)
- Vícejazyčný provoz (router), doménové adaptery pro právní/medicínské kolekce, multi-tenant.
- Evidence pack pro audit, automatizovaný re-embed při změně embedding_version, plán re-indexací.
- Integrace do RAG copilotů, BI a podnikových chatů; SLA pro latenci a dostupnost.
Závěr: jak dělat embeddings chytře a udržitelně
Výběr embeddingů není „souboj modelových názvů“. Jde o disciplinovaný postup: nejprve kvalitní ingestion a extrakce, potom chytrý chunking a metadata, pak teprve porovnání embeddingů na stejné pipeline a vašem korpusu. Přidejte hybrid s BM25, re-ranker a „as-of“ evaluaci. V češtině a CEE prostředí dejte pozor na diakritiku, morfologii a zkratky; pro cross-lingual vyhledávání zvažte multilingvní embeddings nebo jazykový router. Náklady držte na uzdě pomocí IVF-PQ, cache a context budgetu. A hlavně: měřte, logujte, verzujte. Tak dostanete embeddingy, které nejsou jen „hezké v benchmarku“, ale přinášejí měřitelnou hodnotu v reálných aplikacích – od RAG přes vyhledávání až po doporučování a analýzy.